Business & Data Understanding in AI/ML, Part 2


Is my data set ready for machine learning model development? Part of a larger series on Full-Stack AI/ML in Production.
There's a million directions I could take this. I'm not going to be able to give a comprehensive look at data understanding in one blog post. However, I'll give a high level overview of how this looks in structured and unstructured data use cases. I'll also show a specific example using time series data to build a bit more intuition around what can be known about a data set.
Let's Start with a Better Question
What are the goals to hit for preparing data for baseline model training? What can I know about my data, that may impact model accuracy?
Before model development, you have to deep dive on your data. It may be tempting to just get started in a brute force approach, and optimize from there. However, if you don't have a good grasp of certain characteristics of your dataset, you won't know what direction to optimize in model development. What do I mean by "characteristics"? Well, that's exactly what we're going to cover in this post.
Who is this for? How will it help?
My hope is to help product and engineering teams get started working with new AI/ML use cases. I want to equip engineering teams to build a high level intuition around data, and better understand how to improve machine learning outputs.
My intention for this post is to stay high level, and focus on what should be accomplished at this step and the valuable outcomes you can expect from it.
Exploratory Data Analysis (EDA)
This is the step you will take before training a baseline model. First we will go over what Exploratory Data Analysis is, the goals, and then we will go over a specific example to build some intuition.
What is it?
Exploratory Data Analysis is the process of examining and understanding a dataset to uncover patterns, relationships, and potential issues before building predictive models or conducting further analysis. This process includes steps to not only explore the data, but also to clean, format, and perform feature engineering. These steps are the prep work for model development.
EDA Goals
Here are your high level goals for your data set:
- It is clean and correctly formatted: Missing, duplicated, or erroneous data should be handled appropriately. Imputation or removal of missing values, and corrections for errors or outliers, should be done before training.
- Relevant features are included: Ensure that the data has sufficient attributes (features) that are relevant to the problem you’re solving. For instance, when predicting sales, historical sales, temperature, and seasonality are often relevant.
- Appropriate feature engineering is done: Depending on the task, you might need to create new features or transform the existing ones (e.g., normalization, encoding categorical variables).
- Data is at the right granularity: Ensure the data is aggregated or detailed enough to match the business question being addressed. For instance, forecasting daily sales would need data aggregated at the daily level.
So above are the baseline goals just to be able to train the model to start. However, you will want to understand more about your mountain of data. A vast majority of the time, the highest impact change you can make to model output quality is to improve your data set.
To that end, you will also include reviewing distributions, relationships between variables, and identifying patterns. Visualizing data will help you understand if any more preprocessing is needed before continuing.
But first...
Hmmm, Could we Automate EDA?
Yes. For structured data use cases there are libraries often used to automate EDA these days. Check out pandas-profiling, renamed to ydata-profiling: https://github.com/ydataai/ydata-profiling
Definitely recommend you look into tools to automate EDA. However, for the rest of this post, I'm going to go the long way to help make the EDA outputs a bit more intuitive.
Time to Explore
For this section, lets assume you have completed your data cleaning and formatting, and you just want to build a better intuition for your dataset before training. We are going to scope this exploration specifically to a structured data use case with time series data.
What exactly am I looking for as I explore the data? In structured data use cases, you are trying to determine what features within your data set are predictive.
What is a feature? Given a row of data, each column label represents features of that row of data. For example, one row might show the temperature for that week was 70 degrees F. Temperature is a feature of the data set. More on that later.
What to Look for
Your goal is to form better hypotheses about what features result in better AI/ML predictions. This will be your starting place for experimentation in the model development phase.
- Linear relationships
- If two features are directly correlated with one another. For example, temperature and ice cream sales.
- Non-linear relationships
- If there's a correlation, but maybe it's conditional. Like advertising spend and sales revenue. There might be poorly performing ads for example.
- Stationarity.
- Trends, seasonality, cycles, etc.
- Interactions between variables
- Frequency and distribution of data for each feature within the data set.
- Also, include any other questions that may be specifically relevant to your use case
Great, how should I look for this?
Zoom Out, then Zoom In
What's the big picture context here? It's common to first zoom out on the big picture of the data set, then to zoom in with a targeted question. Let's look at the big picture of the data set first, then zoom in for a specific question.
So, what did I mean earlier by the term "characteristics" of a data set. Well, what are some things we can know about a set of data?
Let's suppose we have a mountain of data. Just to anchor us a bit, let's get specific, we have weekly sales data from 45 Walmart stores across the U.S.
Now, there may be some obvious things you can think of that you can begin to understand what this mountain of data is like. If you were sitting in a classroom with your hand up, you might suggest we ask of our dataset:
- How many rows exist in your dataset?
- How many columns are there?
- What is the average value for each column in our dataset?
- What is the min and max value per column?
- I wonder what values fall under the 25th, 50th, and 75th percentiles for each of the given columns?
- Also, what is the standard deviation of the data in each column?
Cool, great start. In fact, usually your Data Analyst is using Pandas which has a super convenient method call for this. .describe()
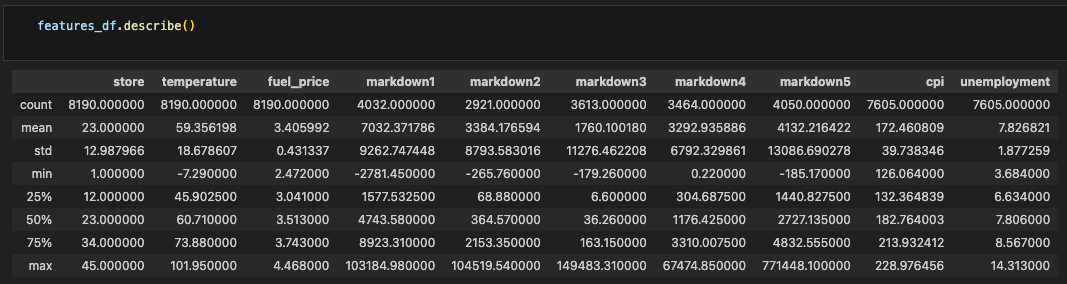
Great, what else should we care about? What might also be useful to know?
- Number of unique values within each feature
features_df.nunique()
store 45
date 182
temperature 4178
fuel_price 1011
markdown1 4023
markdown2 2715
markdown3 2885
markdown4 3405
markdown5 4045
cpi 2505
unemployment 404
isholiday 2
dtype: int64- Range of values, and their frequency in the dataset. How is the data distributed?
features_df.hist(bins=30, figsize=(15,14))
plt.suptitle("Feature Range and Frequency Across All Stores", fontsize=20)
plt.show()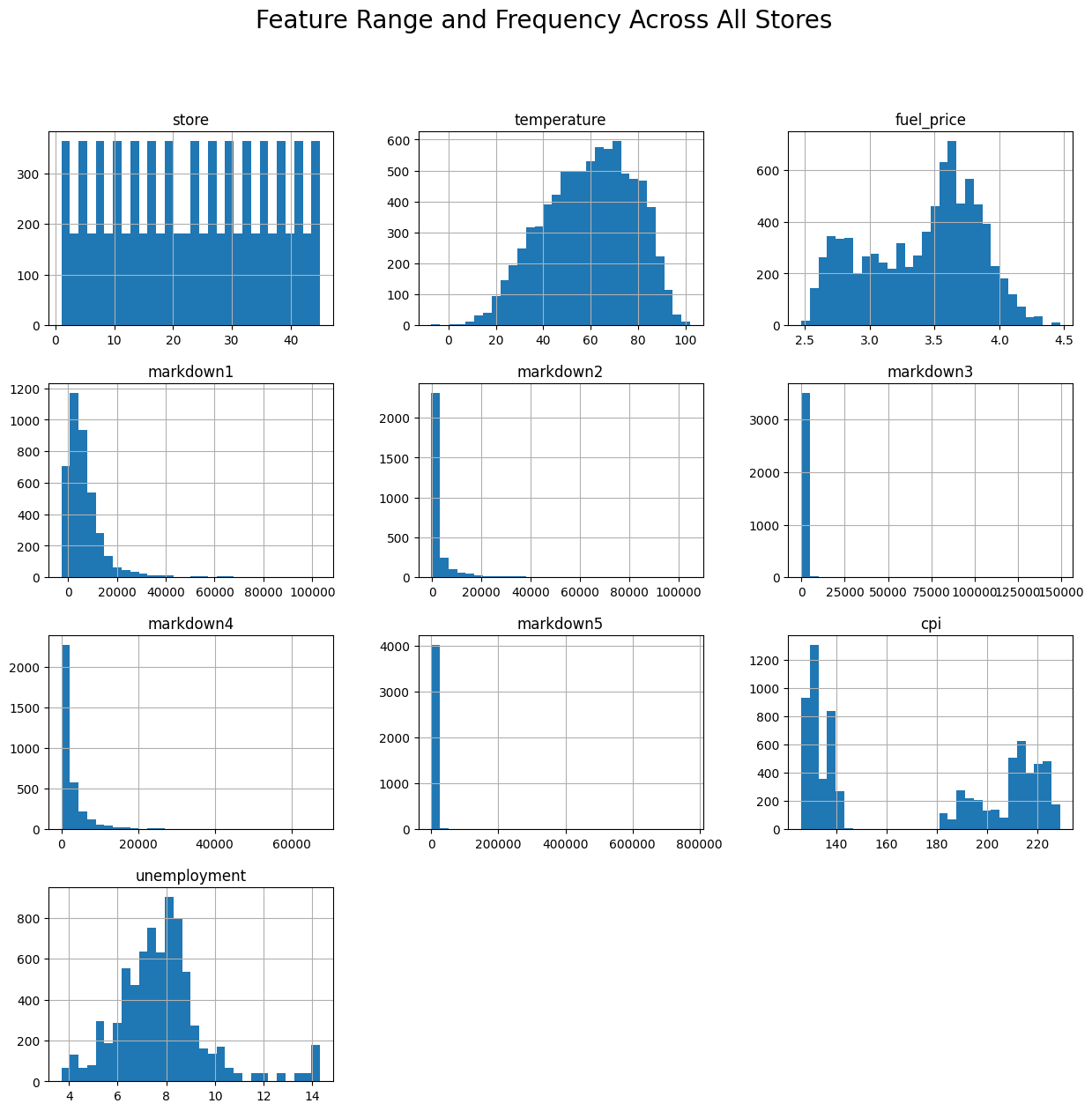
- Plot values over time. Since this is a time series use case.
df_groupedby_fuel = features_df.groupby("date")["fuel_price"].mean().reset_index()
plt.figure(figsize=(12, 6))
plt.plot(df_groupedby_fuel["date"], df_groupedby_fuel["fuel_price"], marker="o", linestyle="-")
plt.xlabel("Date")
plt.ylabel("Fuel Price")
plt.grid(True)
plt.show()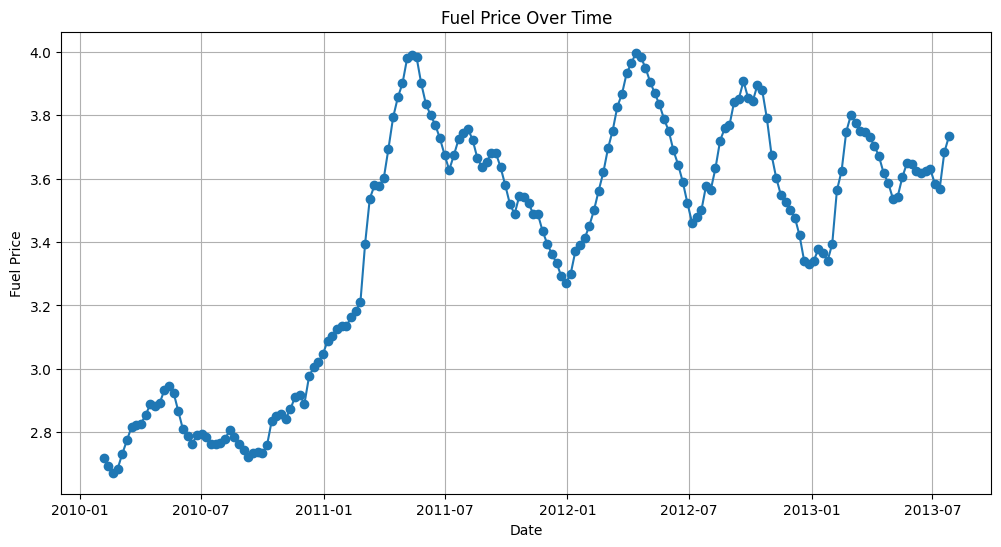
Let's look at three bigger picture features on the same visualization plot. Just to get a bigger picture of how they are trending in our data set.
# Group by 'Date' and calculate the average for each metric
df_grouped = features_df.groupby('date').mean().reset_index()
# Plotting the data
fig, ax1 = plt.subplots(figsize=(12, 6))
# Plotting Unemployment on primary y-axis
ax1.plot(df_grouped['date'], df_grouped['unemployment'], color='tab:blue', marker='o', linestyle='-', label='Unemployment Rate (%)')
ax1.set_xlabel('Date')
ax1.set_ylabel('Unemployment Rate (%)', color='tab:blue')
ax1.tick_params(axis='y', labelcolor='tab:blue')
# Creating a second y-axis for CPI
ax2 = ax1.twinx()
ax2.plot(df_grouped['date'], df_grouped['cpi'], color='tab:green', marker='o', linestyle='-', label='CPI')
ax2.set_ylabel('CPI', color='tab:green')
ax2.tick_params(axis='y', labelcolor='tab:green')
# Creating a third y-axis for Fuel Price
ax3 = ax1.twinx()
ax3.spines['right'].set_position(('outward', 60))
ax3.plot(df_grouped['date'], df_grouped['fuel_price'], color='tab:red', marker='o', linestyle='-', label='Fuel Price')
ax3.set_ylabel('Fuel Price', color='tab:red')
ax3.tick_params(axis='y', labelcolor='tab:red')
# Adding titles
plt.title('Unemployment, CPI, and Fuel Price Over Time')
# Show plot
fig.tight_layout()
plt.show()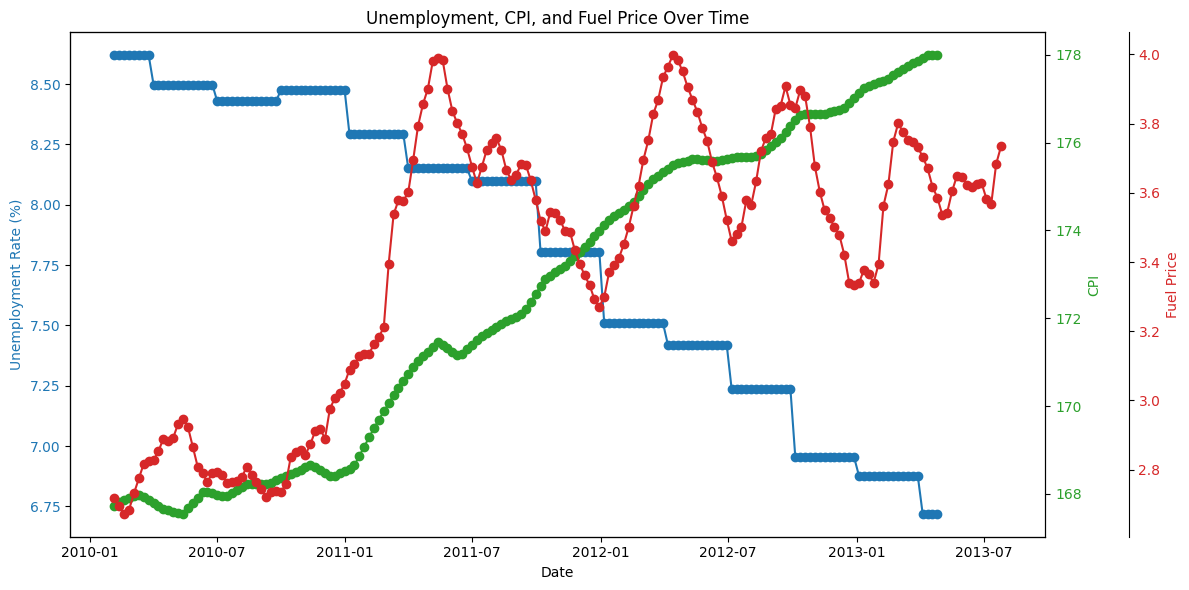
- Let's plot the feature we are aiming to predict averaged over time. Weekly sales.
# Group by 'date' and calculate the average weekly sales
df_groupedby_sales = train_df.groupby('date')['weekly_sales'].mean().reset_index()
# Plotting the data
plt.figure(figsize=(12, 6))
plt.plot(df_groupedby_sales['date'], df_groupedby_sales['weekly_sales'], marker='o', linestyle='-')
plt.title('Average Weekly Sales Over Time')
plt.xlabel('Date')
plt.ylabel('Average Weekly Sales')
plt.grid(True)
plt.show()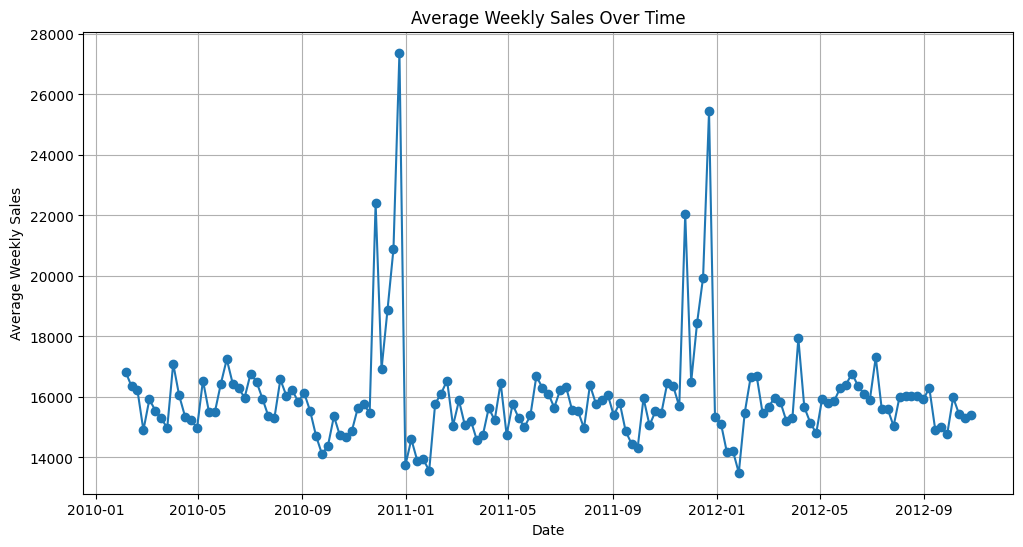
Great. This is a decent big picture view of our time series data. Next, we zoom in and ask some specific questions.
Zoom In
Let's start by anchoring in a research question.
What is our intended goal with this model? Well we have a data set with historical weekly sales, let's create a model to forecast future sales.
What values in our data set might impact buying behaviors?
Great, let's consider temperature then. Do we expect that people will change their buying behaviors in Walmart's physical stores if the temperature changes? This is an example of the type of questions you should be asking, and then answering with EDA.
Also, let's think about this question. Well, if Walmart only sold ice cream very likely we would see a linear relationship between temperature and sales. Do we expect to see a linear relationship given everything they offer? Maybe? Let's check:
correlation = df_groupedby_sales['weekly_sales'].corr(df_groupedby_temp['temperature'])
print(f"Correlation between average weekly sales and average temperature: {correlation}")Correlation between average weekly sales and average temperature: -0.13089770009261642
What does this mean? Well if we saw closer to 1, there would be a positive correlation. If we saw closer to -1, there would be a negative correlation. What we see is pretty close to zero, which is showing not much linear correlation between the two averaged features.
Hmmm, ok, maybe it has an impact, but at certain thresholds? What if the weather is above 90 degrees Fahrenheit? Or below freezing? I would suspect less sales in physical stores. This is one example of what we would call a non-linear relationship. There is a relationship, but there are conditions that trigger it. How can we confirm this? Well, there's lots of ways to approach a question like this. The point of EDA isn't to rush to answer every question, but to write them down and let them inform your research hypothesis during model development.
... However, I know you're curious so I'll show you a quick experiment I ran to find which features are important to predicting weekly sales. This can be done with XGBoost. Turns out that temperature is right up there in terms of importance relative to the other features, ranking at third most important. for my model with the following eval:
Mean Absolute Error (MAE): 1894.8308
R^2 Score: 0.97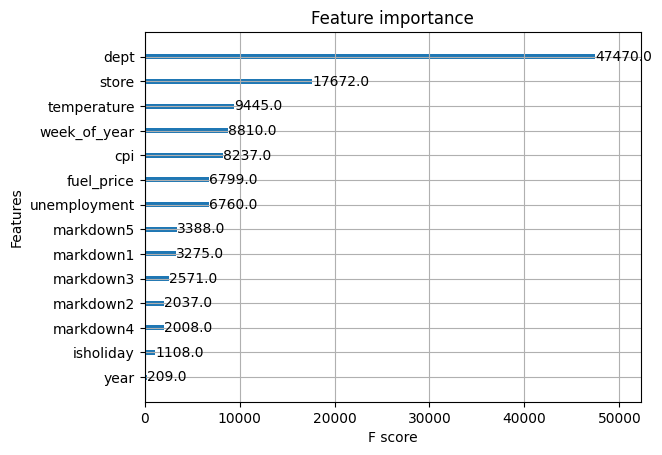
Anyways. If you want to see a bit of exploration with this Walmart sales dataset and some baseline training with XGBoost and LSTM models, feel free to check out my repo and try it yourself. My hope is to give you a small scope starting place to kick off your experiments: https://github.com/synapticsynergy/sales-forecasting-explore
What about Unstructured Data EDA?
Well, the tactical details of how you go about EDA will vary a lot depending on your data type. However, the high level goals remain very similar:
- Ensure Data Quality and Correct Formatting: Verify that the data is complete, correctly formatted, and free of corruption. This step includes identifying missing values, fixing inconsistencies, and handling anomalies or noise specific to the data type (e.g., blurry images, noisy audio, or poorly formatted text).
- Identify Relevant Features: Focus on extracting meaningful features or attributes that capture important characteristics of the unstructured data. This may involve text embeddings, image color distributions, or audio frequency patterns, depending on the data type.
- Apply Appropriate Feature Engineering: Perform transformations or engineering steps tailored to the data type, such as tokenization and stop word removal in text, resizing and normalization in images, or extracting spectral features in audio. This step prepares the data for deeper analysis and modeling.
- Zoom Out for Broad Understanding: Explore the overall structure and composition of the dataset to gain insights into patterns, distributions, and key characteristics. This broader view helps guide subsequent EDA steps and informs hypotheses about what relationships might exist in the data.
- Zoom In with Specific Questions: Dive deeper into specific questions or areas of interest, such as checking for non-linear relationships, clustering similar data points, or visualizing patterns within subgroups of the data. This targeted analysis helps refine hypotheses and shapes the next steps in modeling.
These days common steps I see include:
- Use a pre-trained model to extract embeddings.
- for example BERT to get text embeddings, or Resnet50 for image embeddings.
- Pass these embeddings to T-SNE to reduce dimensions to 2 or 3. Which allows you to plot and visualize multiple dimensions, so you can see the distribution of data and the outliers.
- You will also see PCA and UMAP as other approaches to dimensionality reduction.
- Then zoom in and ask targeted questions of your data set based on your use case.
Remember, the scope of this post isn't to be comprehensive. It's to explain what these concepts are, build some intuition, and help you understand the intended goals to accomplish.
How Much Data is Needed?
The amount of data you need depends on the complexity of the model and the problem domain. Let's start with LLMs since this question comes up a lot. Here's what OpenAI says on this topic
To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples withgpt-4o-miniandgpt-3.5-turbo, but the right number varies greatly based on the exact use case.
For deep learning models that use transfer learning (most do these days), you would be surprised how little data you need to produce meaningful results. Remember to scope your experiments down, and create a reasonably small baseline model. If you are training an image classification problem, consider starting with 50-100 images per class then scale up from there.
Here's a image generation model that can be fine tuned with only around 10 images, which is pretty wild:
The big idea here is scope small for data set size to get your baseline model. The bigger the pre-trained model, the less data you will typically need to fine tune for your use case. Don't over complicate it, scope small and get your baseline model then iterate from there.
Summary
You just learned about Exploratory Data Analysis (EDA), what EDA typically looks like, some intuition around EDA outputs, and volume of data for training baseline models. Now it's time to experiment!