Engineering Design Process for AI/ML Projects


Intro
How can you deploy AI/ML systems while reducing cost, time, and risk as much as possible?
Applying the Engineering Design Process to new AI/ML projects is an efficient roadmap to deploying the three core systems we covered in the last post on Full-Stack AI/ML in Production.
In this post, I will cover how I've seen the Engineering Design Process applied to AI/ML projects over the past 8 years. I will be covering each step with some free templates you can use, why the step is useful, and expected outputs.
It is important to keep this process lightweight, and bias towards simplicity. The Agile Manifesto is your best friend here.
Who's This For?
I'm writing this for Product and Engineering teams as a high level process to approach new AI/ML projects. The goal of this post is focused on process, not system architectures. I will also avoid getting detailed on Agile/Scrum as I assume the reader will be mostly familiar with those ceremonies.
I've personally found that when teams are as close as possible to the Engineering Design Process for AI/ML projects, there are significant benefits. I know, I know, this is very unsurprising. That being said, let's take a detailed look at how to apply this process to AI/ML projects.
Overview
Here's an outline of what we will discuss:
- Define the Problem
- Brainstorm Potential Solutions
- Research
- Define a Potential Solution
- Prototype
- Final Build
Let's dive in!
Define the Problem
Get clear on the desired outcome you want to create with your project.
Template
Output For This Step
Complete the Business Requirements Document.
Why?
This doc is used by massive organizations to efficiently lay the context for the next document the Product Requirements Doc.
This helps clearly define the scope of work, and the intended impact to the end user/business. It answers the questions, “What problem are we trying to solve (or outcome are we trying to create)? and how do we know we’ve hit our intended goal?”
It also serves as documentation for your engineers to anchor their decisions in your primary goals, and can improve the chances for new innovative ideas from the team that are aligned with your goals.
Brainstorm Potential Solutions
Align with your team on potential solutions to the business requirements in the BRD.
Output For This Step
Keep this lightweight and simple. I like to schedule brainstorming session with my team to think about what might be possible as a way to solve business requirements. Document the potential options identified, as you may go back to this later to consider different paths.
Quick Tips
Don't force the solution into a machine learning solution. Allow your team to consider all possible solutions, you may find much more efficient solutions if you keep an open mind. Focus on trade-offs between potential solutions as your guide.
Why?
Brainstorming is a short simple step that allows you to consider multiple paths before building. You may find that a completely different approach will give you a significantly better outcome, and be faster and cheaper to implement.
Research
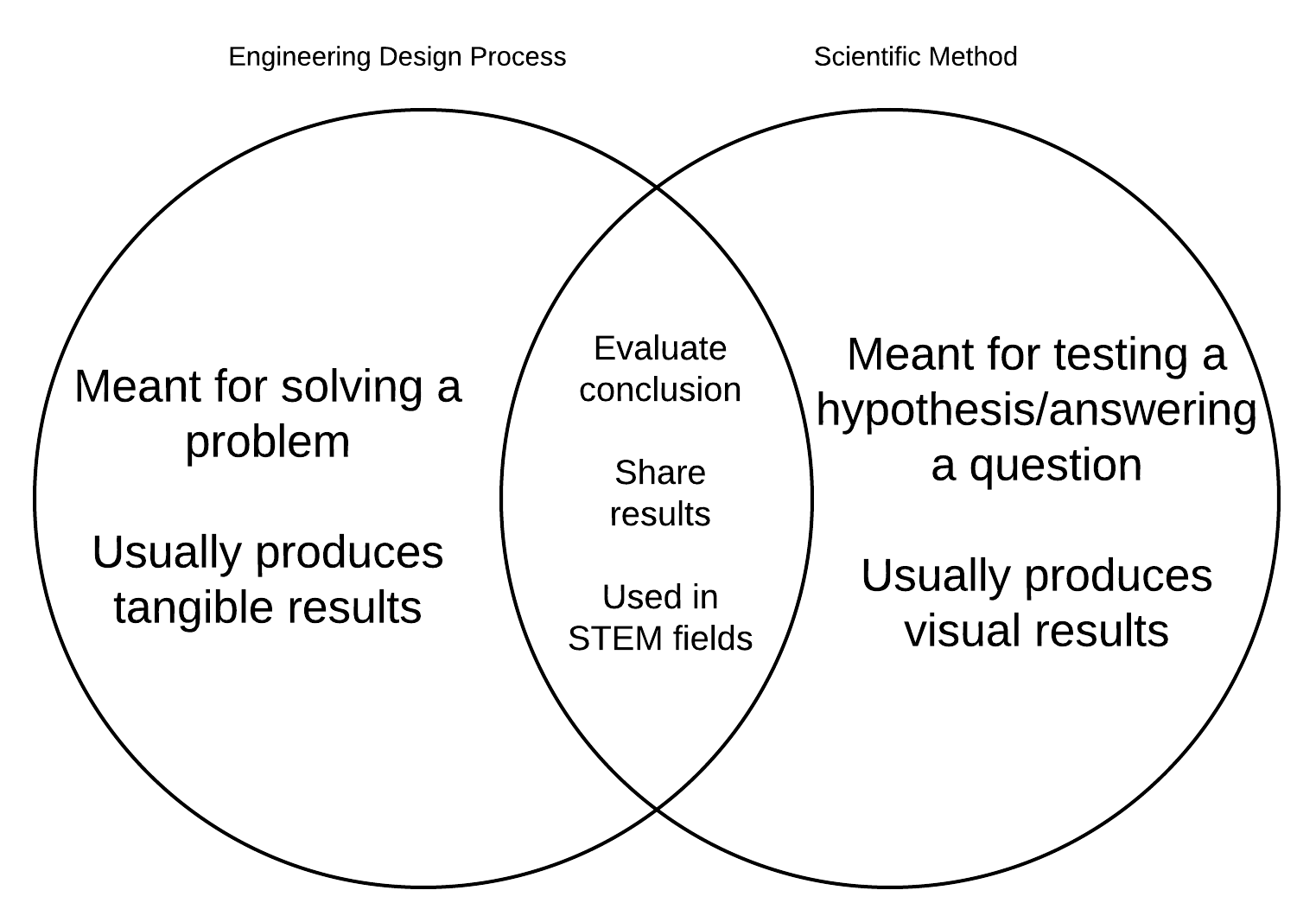
In the context of AI/ML, this is the stage you look at prior work online or in research papers for similar problems you are looking to solve.
This is also the point where data exploration and analysis work is completed. Data quality is likely where you will spend most of your time in this entire system. You should think of this step as similar to laying a foundation for a house. You don't want to hurry through it, you want to be systematic, well documented, and outcome focused. There's a TON more to discuss on data exploration and data quality for model inputs, and I plan dedicate another series of posts scoped just to that. For now, let's keep a high level focus on process.
Output For This Step
In Agile/Scrum, research is completed in Spike tickets.
When you are done, document findings within confluence or notion or whatever your team uses. I usually have a section for SPIKES, and link to the original ticket to keep the context. Whenever possible include data visualization and/or github repo links so you can easily communicate and reference results.
A very useful document to give Data Engineering is Source To Target Mapping (STTM) for the ETL pipeline that will be built. We will cover this in more detail in future posts. Honestly, I have not found a good software tool for this. Most people use excel and it gets really messy and data gets lost. Some people have success using Miro because it's easier to visually show an ERD and you can add lines mapping the data. The big idea here is have a clear way to show which values will map from the data source (a database for example) to the destination (place the data is stored for the model training pipeline). Including data definitions is often very useful as well to communicate the bigger picture and as a reference to look back on.
Why?
Reviewing prior work online and in research papers can help you dramatically improve your project's starting place. Especially today, new tools are coming out at a greater velocity that is making all of this much easier.
Why is data exploration a separate step from data engineering? Nearly all engineers will know the answer to this question already, but the bottom line is that data quality is very often quite low and bad data can completely ruin your chances at model accuracy. It's best to know ahead of resourcing exactly what needs to be done to consistently get the data you need for ongoing model inputs.
Define a Potential Solution
Here you choose a potential solution to try outlined in a simple one page Product Requirements Document (PRD).
Output For This Step
Complete the Product Requirements Document.
Quick Tips
Even though I use the term "Solution", I don't mean this from a technical perspective. A PRD should stay high level and focus on the useful outputs required from the new software to create value for the user. Sometimes product can be a bit too prescriptive without seeing the full picture (haha, you know who you are). By focusing the PRD around software outputs it empowers your engineers to think more broadly about how to accomplish these outputs more efficiently. If this is a struggle on your team, work on biasing your product requirements higher level and you will likely see significant ingenuity as a result.
Why?
A simple one page PRD integrated into a teams workflow can save countless hours of meetings and confusion. I've seen it more times than I can count. I have also seen PRD fix very broken and frustrated teams in record time. It is well worth having this very lightweight tool to align engineering teams.
Prototype
The goal of the prototype is a small scope proof of concept to show that a design accomplishes a desired outcome. It is often used to demonstrate feasibility to stakeholders or investors, and answer any open questions remaining about feasibility. Can often take multiple iterations depending on how new or unexplored the use case is. Significantly cheaper than the final build.
Output For This Step
Some demonstration that helps de-risk the project and ensure it will deliver value after the work is completed.
This is where most Machine Learning Engineers live today. That's why you can easily find blog posts on ML modeling that often doesn't address the bigger systems required for production. It is a very valuable and important step in the process, but also only one step out of many before the Final Build.
The output for this step can be a small scope baseline trained model with evaluation metrics. If IoT is involved, it could be a demo showing how the IoT device responds to pre-trained model outputs from a similar model. The idea here is to give some amount of proof that value can be created, and answering any unanswered questions with proof, before resourcing and investing in the full end-to-end pipelines required for AI/ML in prod.
Quick Tips
For unstructured data use cases, always first consider what pre-trained models you can leverage. Transfer learning is a powerful way to reduce training time and costs for these new use cases. Most ML projects with unstructured data use transfer learning these days. This will also be covered in future posts.
Why?
Done correctly, this should be significantly cheaper than your final build. You want to aim at small scope and prove assumptions before increasing investment. Similarly, ChatGPT didn't start as a massive model, the concept was proven at a much smaller scale before the massive investments.
Final Build
This is where you will put together a plan with your engineers to build the three core systems in production:
- Data Pipeline
- Training Pipeline
- Inference API
More info on this can be found in my previous post on Full-Stack AI/ML in Production.
What You've Accomplished So Far
At this point you have:
- Increased the chances the project delivers valuable outcomes to your end users.
- Increased the chances your team starts down a more ideal path.
- Increased the chances your engineers are aligned to the potential solution.
- Reduced wasted time trying to get answers on requirements.
- Found out quickly if an idea is feasible before hiring too many engineers.
- Built something to demo potential customers and investors for proof of concept.
Now it’s time to clarify the direction, and align the team on the upcoming work.
Task Definition
For all three systems mentioned above, I like the following process to define the work required for Sprints.
- Request for Comments (RFC).
- This is a high level proposal that covers things like system architecture, data persistence, API definitions, and operating cost estimation. This work is completed by an engineer, and is reviewed by the engineering team for comments and suggested improvements.
- I have a generic RFC template I adapt to different software use cases. You can feel free to copy and use this template as a starting place, and adapt it however you like.
- Story Mapping Session.
- Add Tickets to the Backlog.
Again, you will want to have 3 RFCs and 3 Story Maps. This is a ton of work, so scoping them separately is well worth it. In many cases you will have different squads building each system. I encourage you to have a plan for documentation that all teams can align on and look back on for any future changes. RFCs often double as great documentation of decisions that were made and considerations discussed.
Task Refinement
This is where all that hard work comes together for a smooth process your engineering team can action on. You will do your typical Backlog Refinement and Sprint Planning.
At this point, you and your team are aligned and ready to build. 🎉
In future posts we will discuss more details around logging, monitoring, and alerting you will want to have in place for each system to maintain high accuracy on model predictions with production data over time. This will enable you to manage data drift and concept drift proactively.
Summary
Applying the Engineering Design Process to Full-Stack AI/ML in production significantly reduces risk, cost and time. Following this process closer will mean more home runs for your team, and way less confusion.
Up Next
I'll be diving deeper into the three core AI/ML systems for Model Development in production:
- Data Pipelines
- Training Pipelines
- Inference
My goal will be to provide more granular understanding for each of these systems, the components involved, goals for each, and tips for maintaining them in production. My intention is to help Product and Engineering teams understand the high level components required as they prepare for new AI/ML projects.
Teams often find themselves using expensive vendors and systems that could be avoided by understanding the bigger systems at play that vendors and tools are abstracting away. This way you can more easily navigate the trade-offs and make better build/buy/partner decisions as you think about these projects.