Full-Stack AI/ML in Production

Intro
What does it really take to deploy and maintain machine learning systems in production?
You know how it is. There are nearly infinite tutorials on training machine learning models that start with a jupyter notebook then end with a trained model. Then it's... draw the rest of the f**king owl time.

Or maybe you've seen tutorials on AWS SageMaker, and their inference API which feels like it solves the AI in production thing, right?
Well, not exactly. This may be a solid starting place. However, it is essentially a highly manual setup with a lot of tribal knowledge baked into decisions at every point, with very low replicability, pretty low understanding of how you got the current results, and more importantly low understanding of how to fix things like data drift and concept drift if models start producing lower accuracies while deployed.
We can do better than this.
Who is this for? How will it help?
My goal is to cover the high level components and language around what it takes to deploy and maintain AI/ML models in production covering the full lifecycle of model development end-to-end.
My hope is to help product and engineering teams get started in understanding the systems required for new AI/ML use cases. I want to equip engineering teams to better understand the core systems, build a high level intuition around data, and better understand machine learning outputs.
Right now, the internet has way too much information too narrowly focused on tools rather than high level concepts and processes. If you take the time to understand the high level, you will gain the needed frameworks to navigate through the noise.
What Do You Mean by Full-Stack AI/ML?
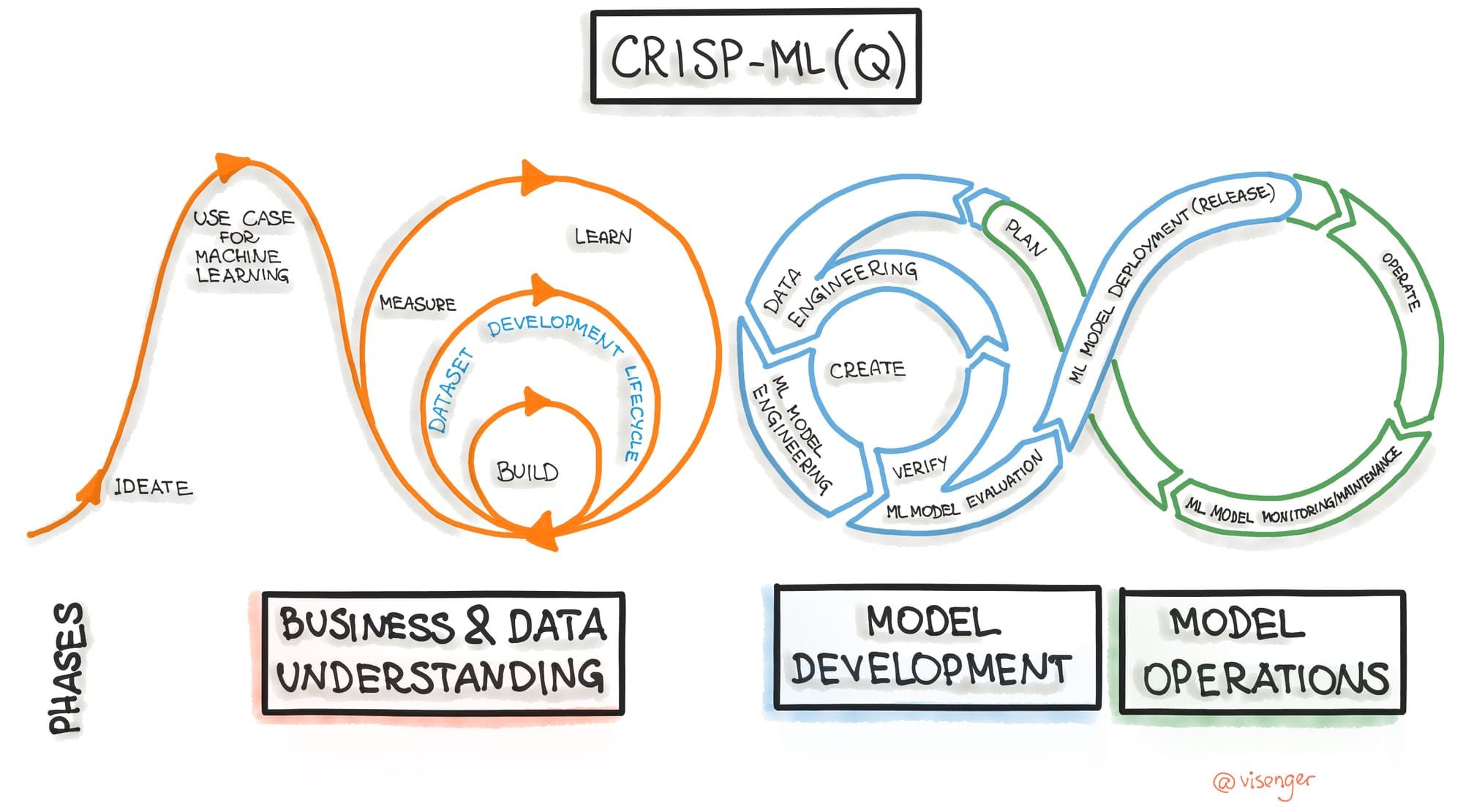
In the context of AI/ML, Full-Stack covers the full machine learning development lifecycle end-to-end, like seen in the Crisp-ML(Q) HLD above. It's everything from idea to production and continuous maintenance/improvements.
Does this work for LLMs?
Yes. Everything I discuss will apply to all model types. These concepts universally apply, even though some parts may be abstracted away if you work with third party vendors like (OpenAi) if you decide to use them.
Ok, now with that out of the way, let's get anchored in some high level concepts that we will dive into in detail in future posts. Here's an overview of the three core phases of the machine learning development lifecycle, and some tips for each.
Business & Data Understanding
Primary Goals
- Define business objectives.
- Define product requirements.
- Explore and clarify existing data and data sources.
- Ensure you have a solid data foundation to begin model training work.
Start with Why?
It's hard to hit a target you can't see.
Like all software investment, if you don't have clear business requirements you will for sure struggle to create value. I know it's tempting to just find a data set, try to derive some predictions then see if these predictions can add business value. Having seen this play out on different teams, my advice is to work it backwards from the value you want to create for the business instead. Great news is, this approach should feel familiar to product and engineering teams.
Data Understanding
After understanding your end goal, this is where you identify your data sources and start exploring the data you have access to and maybe identifying more data sources if required. You can get lost in a lot of detail here, but let's focus on the high level of what matters. How can I know what data inputs will matter?
Two Frameworks for Data Intuition
As you're considering the input data for your machine learning models, use these frameworks:
- Human Level Performance (HLP): If you're working with unstructured data like, images, text documents, audio, etc., ask yourself "Could a human perform these tasks with high accuracy given the same datasets?"
If a human could perform high accuracy with the same data set, your chances of success are reasonably high with your machine learning model. Assuming you have the data and compute you need.
- Predictive Features: If you are working with structured data like CSV, relational DB data, spreadsheets, sensor data, etc. (think rows and columns), then ask yourself "Do we have features, that are predictive?"
What are features in this context?
Each feature represents a variable that can be used to make predictions. For example:
- In a dataset of house prices, features might include the number of bedrooms, square footage, location, and age of the house.
- In a dataset of customer transactions, features might include the amount spent, the time of the transaction, and the type of product purchased.
- In a dataset of sensor data, features might include temperature readings, humidity levels, or timestamps.
The goal is to find data that is predictive, or it is to find data that if a human saw this data they could perform a given task with high accuracy.
Model Development
Primary Goal
- Develop and deploy systems for model inference and ongoing updates.
Prototyping
Before architecting a full solution, and writing production code, you will want to de-risk your projects first by prototyping. In AI/ML this usually means carving out some data to train a model for baseline performance. It also often includes prototyping other aspects to answer any open ended questions before a full implementation. After your core project assumptions have been de-risked with prototypes, you are ready to plan and build your production systems.
Three Core Systems
There are three core systems that make up every ML model development use case:
- Data Pipeline: Gather input data and transform for model inputs. So basically ETL.
- Training Pipeline: Ongoing model training.
- Inference: Trained model deployed for access. Could be via API, batch inference that saves results in a database, or even serving on edge with IoT or in the browser.
That's it at a very high level. These are the categories you should begin thinking about as you consider bringing new AI/ML models to production. We will go deeper in follow up posts in this blog series.
But what if the model is already trained?
I'm so glad you asked. This does simplify things in some regards because whomever trained the model has the data set and training covered on your behalf. However, it is important to consider your original business and product requirements before moving forward.
For example, you may have a use case filtering out toxic user submitted text in comments posted online. Good idea, right?
Well, what does that data set look like? What kind of bias might the individuals have flagged as "toxic"? You could inadvertently be filtering out views of one political ideology or race or religion. Basically, just fill in the blank with any bias someone labeling a data set could have. As an aside, there are pre-trained models that take this into consideration, like the unbiased model referenced here.
In other words:
- Consider the data set and potential biases.
- Consider model evaluation metrics, which show how well the model performs for certain tasks. Verify these metrics are acceptable for your business and product requirements.
So basically, while you're not building the data pipeline, you are still doing some of the work required. Same can be said about the training pipeline since you are reviewing the evaluation metrics against your business case.
Handling Non-Deterministic Outputs
How can you trust or rely on outputs you are uncertain of?
Answering this question well is core to many machine learning use cases, and there are a few ways this is handled. Oftentimes in production you are able to leverage a confidence score, then route to a different model or code path when confidence is lower than a certain % threshold. This option isn't always available, but keep an eye out for this pattern as it's pretty useful.
For LLMs, this is a work in progress, but some solid work has been open sourced by Meta called Llama Guard.
The big picture here is, you will want to leverage both AI models and deterministic code to manage model outputs for different use cases. It's definitely strange at first, creating a system that doesn't have a definite result. But consider how physics has benefited from the Uncertainty Principle. Just because something is non-deterministic, doesn't mean it has to be too difficult to work with. If we embrace a mixture of deterministic and non-deterministic software, the result is quite powerful.
Model Operations
Primary Goals
- CI/CD.
- QA and Tests.
- Logging, Monitoring, Alerting.
- Maintaining Model Accuracy.
Ongoing Maintenance and Updates
How can you ensure model predictions remain high accuracy on production data? If model accuracy remains high, how can we be sure the model remains useful over time?
These are the core questions we want to answer as we tackle model operations.
Most of the concepts in DevOps are the same for ML model operations. So I want to mostly focus on Observability (aka O11y) as I think this is the main area of difference that is useful to understand.
Observability
Software engineering teams are usually well versed in logging, monitoring, and alerting. The data and behavior you are looking for with MLOps is a bit different. Here's a high level for what you will want to implement:
Logging
- Inference Logs: Log each prediction, including inputs, outputs, and any associated metadata (e.g., timestamps, model version).
- Model Performance Metrics: Log metrics such as accuracy, precision, recall, and other relevant performance indicators.
- Data Quality Checks: Log any checks performed on the incoming data, such as missing values, outliers, or distribution shifts.
- Model Drift Indicators: Log statistical metrics comparing current input data distributions to the training data distributions to detect drift.
- System Metrics: Log system-level metrics like CPU, memory usage, and latency to monitor infrastructure performance.
- Error Logs: Log any errors encountered during model execution, including stack traces and context for debugging.
Monitoring
- Model Performance Over Time: Continuously track metrics like accuracy, precision, recall, and others to detect performance degradation.
- Data Drift and Concept Drift: Monitor for changes in the input data distribution (data drift) or shifts in the underlying data relationships (concept drift).
- Resource Utilization: Monitor infrastructure resources such as CPU, GPU, memory, and network usage to ensure the system operates within acceptable limits.
- Latency and Throughput: Monitor the time taken to serve predictions and the number of requests handled to ensure the system meets SLA requirements.
- Anomalies in Predictions: Monitor for unusual patterns in the predictions, such as a sudden increase in error rates or unexpected outputs.
Alerting
- Performance Degradation: Trigger alerts if performance metrics like accuracy or recall drop below a predefined threshold.
- Data Drift Detected: Alert if significant data drift is detected, indicating that the input data has changed from the training data.
- Infrastructure Issues: Set alerts for high resource utilization (e.g., CPU, memory) or if latency exceeds acceptable limits.
- Error Rates: Alert on an increase in error rates, particularly if the model starts failing or throwing exceptions more frequently.
- Anomalous Predictions: Trigger alerts for patterns in predictions that deviate significantly from expected behavior, such as a spike in negative predictions or outlier outputs.
Future Posts
I plan to cover in detail the three core phases of machine learning development I mentioned above. First, I will focus on the "What" to give you a north start to aim at for your projects. Then I will cover the "How", which will be methodology focused. Here's what you can expect in future posts:
Business & Data Understanding
In the Business & Data Understanding series, I will focus on better prioritizing, preparing, and leveraging data for business impact.
We will answer the question:
- How do I know when data set is ready for baseline model training?
- What exactly needs to be accomplished to prepare a dataset for training?
- How much data is needed?
- What is the purpose of splitting data sets into training set, test set, and validation sets? And what should the ratios be between them?
Model Development
My goal in future posts on Model Development, in this blog series, is to focus on helping engineering teams understand the high level components and language around these core systems. So I will be covering all three with high level concepts and language.
This blog series will intentionally sidestep tools you can use, because there's way too much of that out there already and it misses the big picture. Teams often find themselves using expensive vendors and systems that could be avoided by understanding the bigger systems at play that vendors and tools are abstracting away. This way you can more easily navigate the trade-offs and make better build/buy/partner decisions as you think about these projects.
Model Operations
My goal in these future posts will be to get detailed on what you will want to watch for to ensure your deployed model accuracy remains high, and how you can handle issues like data drift and concept drift in production.
Engineering Design Process for AI/ML
To put all of this into action, you need a process. Ideally, one that is lightweight. Most AI/ML projects that fail are as a result of the front end of the development process. The problem isn't defined well enough, or the data isn't well understood.
In the this follow up post, I will be going into detail on an approach to these projects I've seen work well over the past 8 years I've worked with AI/ML. The high level overview is essentially just the Engineering Design Process, and kept very lightweight. Agile Manifesto is your best friend here:
- Define the Problem
- Brainstorm Potential Solutions
- Research
- Define a Potential Solution
- Prototype
- Final Build
In this next follow up post, I give away free templates to help you and your team stay on track and make faster progress. Here's a link to my post about applying the Engineering Design Process to AI/ML projects.
Summary
Full-Stack AI/ML covers the full machine learning development lifecycle end-to-end. This includes three core phases:
- Business & Data Understanding
- Model Development
- Model Operations
In future posts, we will go deeper into each phase with the goal of helping engineering teams understand the high level concepts and language in each section. So they can get started building AI/ML systems, more easily navigate trade-offs working with vendors or pre-trained models, and gain more data intuition as they think about applying these systems to business cases.
Next up, I will be going deeper on the Business and Data Understanding phase.