Most Popular CV Model Types


What if a baby monitor video stream could alert you if your baby is in a dangerous position at night? What if you could use sign language to control your tv and speakers? What if cars drove themselves? These are some of the interesting tasks that computer vision makes possible.
Computer Vision Model Types
My intention is to stay high level, and give a general introduction to supervised learning types of computer vision. We will start with more general computer vision types, then go deeper. For the purposes of this post we will define a model type by its outputs, not by the model architectures.
Research often builds on itself like lego blocks, and computer vision is no exception. As you will see below there is a logical progression to the types of models that have been created over time. Below are the most common model types in computer vision that require supervised learning.
Object Recognition
Object recognition is really the top level type for the following model types. Every computer vision model type below is an Object Recognition model. Below is a rough representation for how these main model types relate to one another.
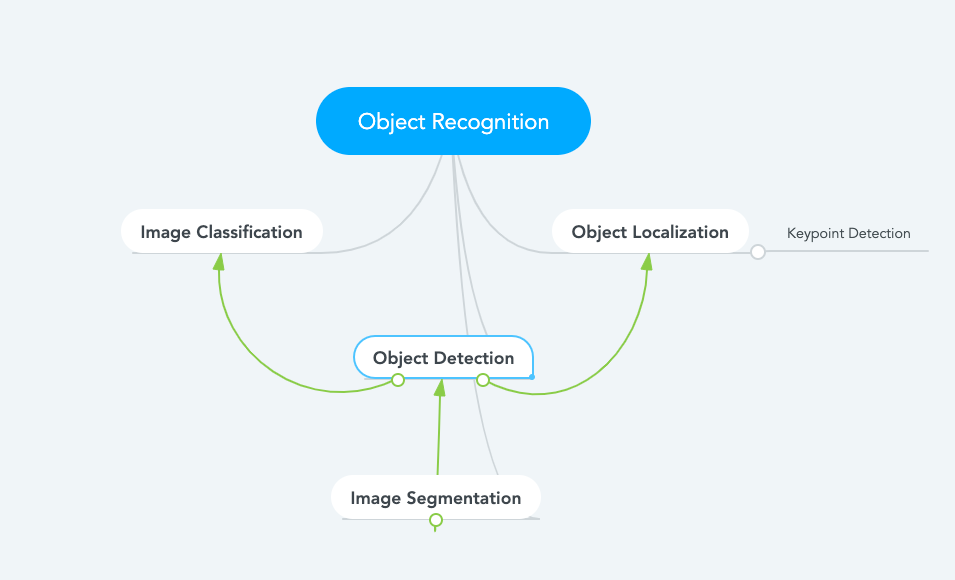
Object Detection
This is what most people think about when they hear computer vision. Object detection is a combination of the two following tasks:
- Object Localization: Locating one or more objects within an image.
- Image Classification: Categorizing objects. We talk about this in a bit more detail below.

As you can see in the picture above, multiple objects are detected, labeled, and bounding boxes locations are output by the model.
Bounding Box Detection
One important note about models that detect bounding boxes: these models don't output images with these rendered boxes and class labels. So what do they output? And how do we know the exact location of the bounding boxes within an image? I'm glad you asked. Here is a link to a popular model architecture for bounding box detection: Faster rcnn. When following that link, pay special attention to the model Inputs and Outputs. The model I linked above will output a response like this:
{
"predictions": [
{
"detection_boxes": [
[
0.645104,
0.40624,
0.93266,
0.659505
]
...
],
"detection_classes": [
28.0
....
],
"detection_scores": [
0.511799
...
],
"num_detections": 1.0
}
]
}
You will notice that the bounding boxes output by this model are floats. Based on their position in the array they reference these pixel locations within an image: [ymin, xmin, ymax, xmax]. So what does that mean? If you have an image that is size 224 X 224 pixels, then you multiply those values by the height or width to get the pixel location of the bounding box. So that means the bounding box for a 224 X 224 image will be located at these pixel locations [145, 91, 209, 136]. Here is the equation to see a bit more clearly:
(left, right, top, bottom) = (xmin * im_width, xmax * im_width,
ymin * im_height, ymax * im_height)Oops, I said I would stay high level. My bad. The reason I included these details is to help you build an intuition for approaching new models by looking at their inputs and outputs.
Now that we understand bounding boxes, what if we wanted to get even more accurate? What if we could understand where an object is located within an image without including the background? Turns out we can. Enter, Image Segmentation.
Image Segmentation

For image segmentation, a model will classify each pixel in an image. That means that the class of "dog" above is applied to the pixels where the dog is located within the image. There are multiple types of image segmentation: Instance Segmentation, Semantic Segmentation, and Panoptic Segmentation. Check out this post for more details different types of image segmentation.
Here is an example of a popular image segmentation model architecture Mask rcnn. This time, I won't paste the outputs. Follow that link to Tensorflow hub to see the inputs and outputs for this model. I plan to cover mask rcnn in greater detail in a future post.
So How Is This Useful?

It's not really, it's just an expensive toy. Just kidding it can be pretty useful. Image Segmentation is being applied to a lot of medical use cases including cancer cell detection. Self driving cars are using image segmentation models as a component to accurately track surroundings. There are a ton of other use cases, but I can leave it there for now.
Image Classification
This one might look familiar, since I used it in my last post Intro to Image Annotations. But what is it exactly?
Image classification simply answers the question, "what kind of thing is in this picture?"
Why is this useful? Anytime you want to know what is in a picture or video without actually looking at it, this is useful. Technically Object detection includes Image Classification as referenced above. However, there are a few variants I wanted to highlight here: Single Label Image Classification, Multi Label Image Classification, and Fine Grained Image Classification.
Single Label & Multi Label Image Classification
This is somewhat straight forward. Single label image classification models predict one label when given an image like "cat" or "dog". Multi label image classification models predict multiple labels given one image, like: "dog", "brown_fur", "running", "long_hair", etc.
Fine Grained Image Classification
Fine Grained Image Classification is when you want to identify different types of things within a defined category. A category might be trees, and you want to identify the kinds of trees that exist in your area.

In the real world, you will often see object detection performed first, then passed to a fine grained image classification model get more precise classification. There are a lot of different techniques that are applied here, but to stay high level I'll stop there.
KeyPoint Detection
KeyPoint detection is also what it sounds like. A Keypoint model will detect specific points within an image. There are a large variety of KeyPoint detection models, for now I'm going to just point out one of the most popular, Pose Estimation.
Pose Estimation
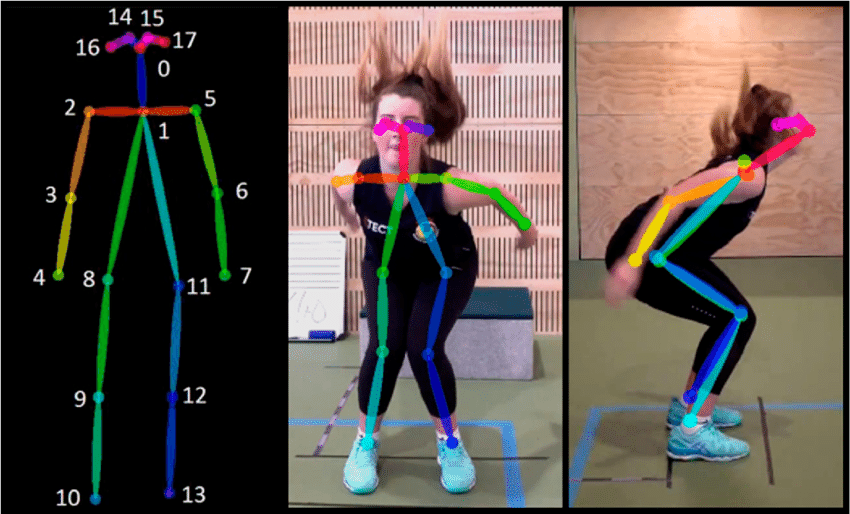
The model output looks something like this:
{
"score": 0.32371445304906,
"keypoints": [
{ // nose
"position": {
"x": 301.42237830162,
"y": 177.69162777066
},
"score": 0.99799561500549
},
{ // left eye
"position": {
"x": 326.05302262306,
"y": 122.9596464932
},
"score": 0.99766051769257
},
{ // right eye
"position": {
"x": 258.72196650505,
"y": 127.51624706388
},
"score": 0.99926537275314
},
...
]
}
This output was sourced form Tensorflow blog, and you can read more details there.
Summary
So that was a high level overview of the most popular supervised computer vision model types. There are a lot of model types I didn't cover, but wanted to narrow it down to the ones you are most likely to work with.
Now for some good news. With this blog we are focussing on data annotation and organization. Even though there are a lot of different model types, turns out they all can use the same annotation format. Coco Annotation format. In my next post, I will be covering this format in detail.